
The next generation of AI will not be built in offices or labs. It will be forged in industrial-scale “AI superfactories” that look more like power plants than traditional data centers.
At the center of this shift is Microsoft’s new Fairwater AI data center in Atlanta, a purpose-built AI superfactory packed with Nvidia GB200 and, soon, GB300 GPUs. It is part of a new distributed Azure AI network that stretches from Wisconsin to Georgia and, over time, across the United States. Source+1
This piece dives into what Fairwater actually is, how it works, and why it matters for the wider hyperscale AI infrastructure race.
What Is Microsoft’s Fairwater AI Data Center?
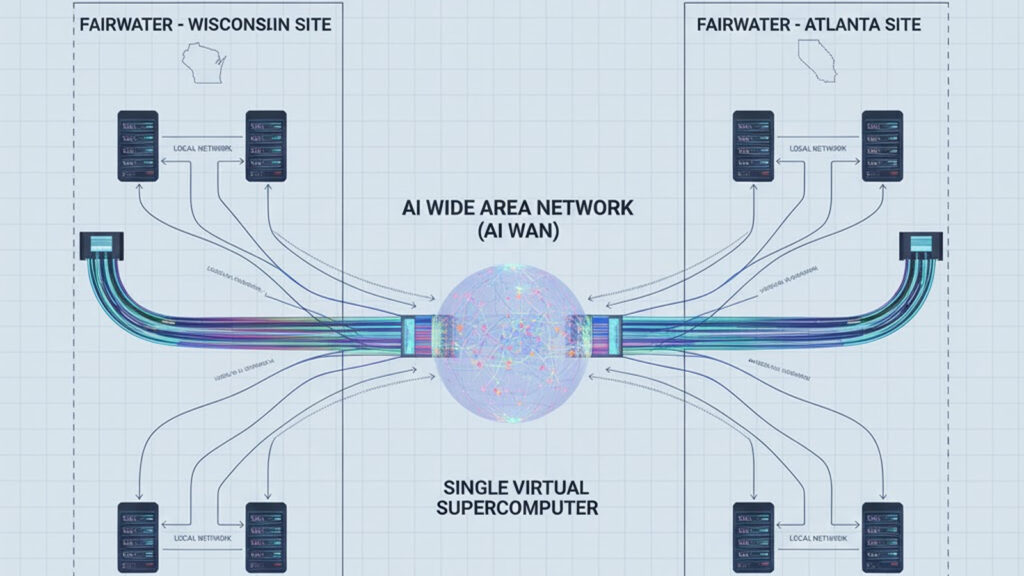
Microsoft describes Fairwater as a new class of AI data center that does not stand alone. Instead, each site plugs into a dedicated AI wide-area network (AI WAN) to form a “virtual supercomputer” spanning multiple locations. Source+1
The Atlanta facility, often referred to as Fairwater 2, is:
- A two-story AI superfactory outside Atlanta, Georgia
- Built on roughly 85 acres, with over a million square feet of space
- Densely packed with Nvidia GB200 NVL72 rack-scale systems, each rack holding up to 72 Blackwell GPUs
- Connected via a new flat, high-bandwidth network that can scale to hundreds of thousands of GPUs in a single logical cluster Source+2The Official Microsoft Blog+2
This Microsoft Fairwater AI data center is already live, having begun operation in October, and is directly connected to the original Fairwater complex in Wisconsin. Together they anchor a new generation of AI data centers in Atlanta and beyond that are designed specifically for large-scale AI training and inference, rather than generic cloud workloads. Source+1
Inside the AI Superfactory: Architecture and Hardware
From “data center” to “AI factory”
Traditional cloud data centers are optimized to run millions of independent applications. Fairwater inverts that model. It is optimized to run a single enormous job across millions of hardware components, such as training a frontier-scale model or running continent-wide inference. Source
That shift shows up in three layers: compute, networking, and cooling/power.

1. Nvidia GB200 and GB300 at hyperscale
At the heart of Fairwater are Nvidia GB200 NVL72 systems:
- 72 Nvidia Blackwell GPUs + 36 Grace CPUs per rack, tied together with NVLink so the whole rack behaves like one massive GPU
- Up to 1.8 TB/s of GPU-to-GPU bandwidth per rack
- Over 14 TB of pooled memory per GPU in the NVL72 domain, thanks to aggregated HBM and system memory The Official Microsoft Blog+2NVIDIA+2
Microsoft’s architecture blog explicitly calls out support for both Nvidia GB200 and GB300 GPUs, integrated into a single flat network that can scale to hundreds of thousands of accelerators.The Official Microsoft Blog
Why this matters:
- GB200/GB300 are designed to run trillion-parameter models in real time. Nvidia claims up to 30× faster real-time inference for trillion-parameter LLMs compared with previous-generation systems.NVIDIA+1
- For customers, that means lower latency, lower cost per query, and the ability to run larger models closer to end users.
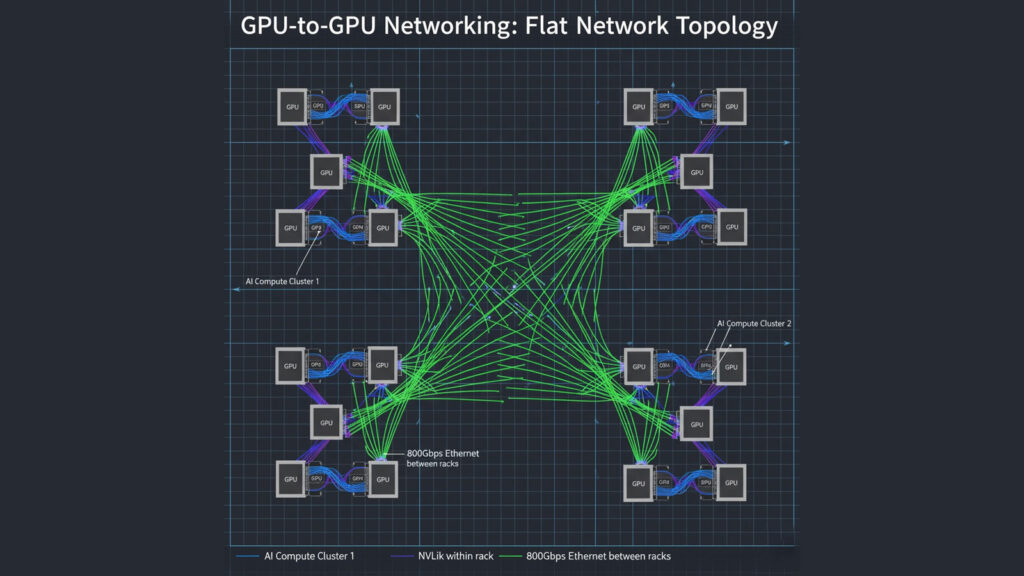
2. Flat, GPU-first networking
Fairwater’s network design is as important as the chips:
- Single flat network: instead of nested Clos topologies, Microsoft uses a flat architecture that lets all GPUs participate in a single coherent cluster.
- 800 Gbps GPU-to-GPU connectivity using Ethernet-based scale-out networking, plus NVLink inside each rack for ultra-low latency.
- AI WAN backbone: more than 120,000 miles of new fiber across the US tie Fairwater sites and prior Azure AI supercomputers into one AI superfactory.The Official Microsoft Blog+1
The key idea: you can treat GPUs in Wisconsin and Atlanta as part of the same logical machine for training and inference, while maintaining latency low enough for modern distributed AI workloads.
3. Two stories up, water use way down
The Atlanta AI superfactory is built vertically to combat the speed-of-light problem:
- Two-story building design: racks are arranged in three dimensions so cable runs are shorter, which reduces latency and improves reliability and cost.
- Closed-loop liquid cooling: servers connect into a facility-wide liquid system that uses water only once at initial fill, then recirculates it with no evaporation. The initial fill is roughly equal to what 20 homes use in a year, and is designed to last six years or more. The Official Microsoft Blog
Rack-level power density can reach about 140 kW per rack and 1.36 MW per row, pushing far beyond traditional air-cooled limits. The Official Microsoft Blog+1
For hyperscale AI infrastructure, this cooling and building architecture is what makes GB200/GB300 deployments feasible at meaningful scale.

Power, Latency, and Why Atlanta Matters
Why Atlanta?
Microsoft chose Atlanta for Fairwater 2 primarily for power and grid resilience:
- The site targets “4×9 availability at 3×9 cost” for grid power, meaning high reliability without an explosion in cost.
- Because of that reliability, Microsoft can skip traditional on-site diesel generation and UPS redundancy for the GPU fleet, which improves time-to-market and lowers cost per training run.The Official Microsoft Blog
Atlanta also gives Microsoft better latency to East Coast enterprises and consumers compared with its Midwest sites, while being close enough to Wisconsin for high-speed inter-site links on the AI WAN.
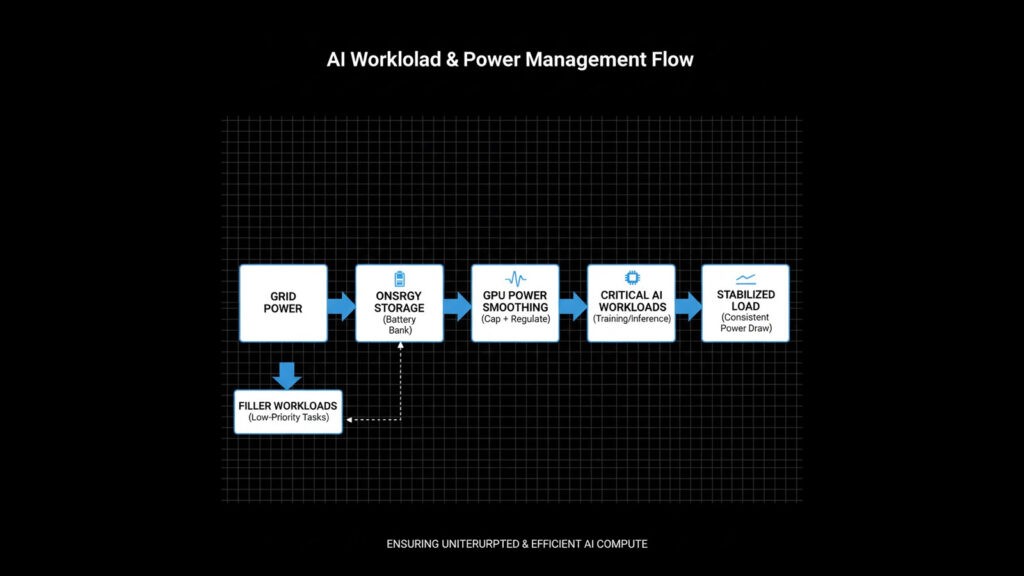
Tackling power oscillations
Running hundreds of thousands of GPUs on a single job can cause serious power oscillations on the grid when load surges or drops. Microsoft says it has co-developed several mitigation techniques, including: The Official Microsoft Blog
- Software that spins up “filler” workloads during troughs to smooth power draw
- Hardware controls that enforce GPU power thresholds
- On-site energy storage to buffer short-term spikes
This grid-friendly design will become a competitive differentiator as regulators and utilities scrutinize AI data centers in Atlanta and similar hubs.
The Data Center Arms Race: Context and Spending
Fairwater is not being built in isolation. It sits in the middle of a global AI infrastructure arms race.
Hyperscalers are spending trillions
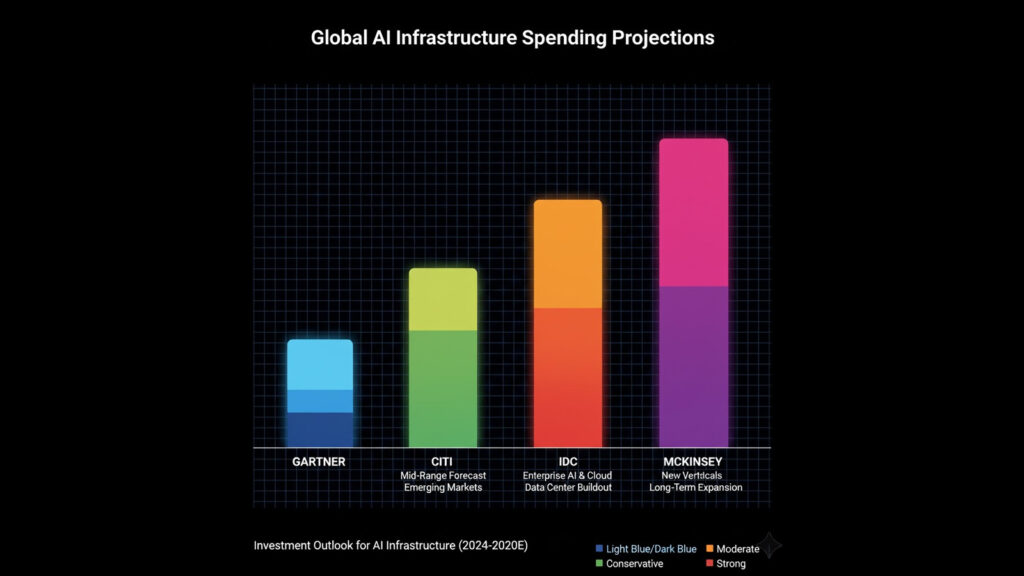
- Gartner estimates worldwide AI spending (including infrastructure) will reach nearly $1.5 trillion in 2025, with persistent demand for accelerated compute driving infrastructure investments.gartner.com
- Citigroup recently projected that Big Tech’s AI-related infrastructure spending alone will surpass $2.8 trillion by 2029, with an additional 55 GW of power required globally.Reuters
- IDC expects AI infrastructure spending on accelerated servers to grow at a 42 percent CAGR through 2029, with accelerated systems making up over 95 percent of server AI infrastructure spending.IDC
- McKinsey estimates that global data centers will need around $6.7 trillion in capex by 2030, with roughly $5.2 trillion of that tied specifically to AI-capable facilities.McKinsey & Company
In other words, global AI infrastructure spending is measured in trillions, not billions, and Fairwater is one flagship in a very large fleet of projects.
AI data centers Atlanta vs competitors
Microsoft is not alone:
- Amazon, Google, Meta, Oracle, and newer players like xAI are all deploying Nvidia H100, B100, and GB200 clusters at similar or larger scales.The Next Platform
- OpenAI itself has signed massive infrastructure deals with both AWS and Oracle, worth tens to hundreds of billions, to secure access to Nvidia-powered facilities beyond Microsoft’s own data centers. The Guardian+1
However, Microsoft’s AI superfactory strategy stands out for one reason: instead of a single “world’s biggest supercomputer” site, it is building a network of Fairwater sites that function as one logical AI factory.

Why AI Superfactories Change the Cloud Game
1. New economics of training and inference
By concentrating Nvidia GB200 and GB300 GPUs into extremely dense clusters, Microsoft can:
- Boost utilization: The AI WAN and flat network let them allocate workloads across Fairwater sites dynamically, so fewer GPUs sit idle.The Official Microsoft Blog
- Lower cost per token: Better utilization and high rack density drive down the cost of both training and inference.
- Offer fungible capacity: A customer using Azure AI does not need to care whether their job runs in Wisconsin or Atlanta. The superfactory hides the complexity.
For enterprises, this makes it more realistic to train custom large models or deploy high-traffic copilots without building their own AI data centers.
2. Latency as a first-class constraint
As models grow and response times shrink, latency is no longer just a networking metric. It is a product feature.
Fairwater tackles latency at several layers:
- Shorter cables and two-story layouts inside buildings
- NVLink and 800 Gbps links between GPUs and pods
- AI WAN to route traffic across sites based on workload type, keeping latency-sensitive training and inference closer to the edge when neededThe Official Microsoft Blog+1
This is crucial for emerging use cases like real-time copilots embedded in productivity suites, AI agents in financial trading, and low-latency autonomous systems.
3. Sustainability signaling
Although AI superfactories consume huge amounts of power, Microsoft is trying to position Fairwater as more sustainable than previous data center generations:
- Closed-loop liquid cooling that uses almost no operational water
- High density per square foot, so more compute fits in a smaller footprint
- Grid-friendly power smoothing and energy storage to avoid destabilizing local infrastructure Official Microsoft Blog
The broader industry will watch closely to see if these design choices translate into lower effective carbon and water footprints per unit of AI compute.
What This Means for Enterprises and Developers
If you are building on Azure or planning AI workloads, Microsoft’s AI superfactory approach has practical implications.

1. Higher-end GPU SKUs in managed services
Expect more Azure services to surface Nvidia GB200/GB300-class accelerators behind familiar abstractions:
- Azure OpenAI Service / Azure Models
- Managed fine-tuning and RLHF pipelines
- Vector search, RAG, and multi-agent orchestration platforms
Most users will never see the words “Fairwater AI data center” in a portal, but they will feel the effects in faster training, lower latency, and support for larger context windows.
2. Region and data residency strategy
As AI data centers in Atlanta, Wisconsin, and other Fairwater regions come online, Microsoft gains more flexibility around:
- Data residency: training and inference within specific jurisdictions
- Compliance: aligning sensitive workloads with particular regulatory zones
- Latency-aware routing: placing latency-critical workloads closer to users while still leveraging the AI superfactory backbone
For enterprises, this underscores the need to align cloud region strategy with AI roadmap decisions rather than treating them separately.
3. Vendor concentration and risk
On the flip side, hyperscale AI infrastructure is massively concentrated:
- A handful of clouds control access to most Nvidia GB200/GB300 capacity.
- Lock-in risks rise as higher-level AI platforms abstract away the underlying hardware.
Many large organizations are already pursuing multi-cloud or hybrid AI strategies to hedge against this, often combining Azure with AWS, Oracle, or on-prem Nvidia DGX/GB200 clusters.
FAQ: Key Questions About AI Superfactories
Is Fairwater only for Microsoft’s own AI models?
No. Fairwater supports Microsoft’s internal models, partner models such as OpenAI’s, and third-party workloads built on Azure AI infrastructure. Source+1
How many GPUs does the Atlanta site have?
Microsoft has not published an exact count, but official materials describe hundreds of thousands of Nvidia GPUs across the Fairwater network, and the architecture is designed to scale well beyond that.Source+1
Why use Nvidia GB200/GB300 instead of custom chips?
Microsoft does have its own Azure-branded accelerators, but Nvidia’s GB200 and GB300 remain the highest-end, most ecosystem-supported options for frontier-scale models today. Their NVLink domains and Blackwell architecture are particularly well-suited to AI superfactory designs.NVIDIA+1
What about the environmental impact?
Even with advanced cooling and grid-friendly power management, AI superfactories are extremely resource-intensive. The debate over long-term sustainability, regulation, and community impact is just beginning, especially as data center projects push into the multi-gigawatt range worldwide.McKinsey & Company+1
The Future: From One Superfactory to a Planet-Scale AI Grid
Fairwater is likely a first draft of what AI infrastructure will look like over the next decade.
Expect to see:
- More Fairwater-style sites across North America, then Europe and Asia, as Microsoft doubles its data center footprint in the next two years.Wall Street Journal+1
- Even denser racks as Nvidia GB300 and later architectures push power and cooling demands further.
- Deeper integration with telco networks and edge sites, turning the AI WAN into a truly planet-scale AI grid.
- Regulators and communities pushing back on power and water consumption, forcing more innovation in efficiency, siting, and grid integration.
For now, Microsoft’s Fairwater AI data center in Atlanta gives a clear signal: the future of AI is not just about smarter models. It is about the industrial infrastructure that makes those models possible.
If you are planning your own AI roadmap, treat AI superfactories and hyperscale AI infrastructure as core context, not background noise. The capabilities, costs, and constraints of facilities like Fairwater will quietly shape what is possible for everyone building on top of the cloud.